Why AI Coding Agents Lose the Plan - and Why It's a Memory Problem, Not an Intelligence Problem
Context-window decay is a memory problem, not an intelligence problem. Learn why long prompts lose the plan and why explicit acceptance criteria survive where prose plans fail.
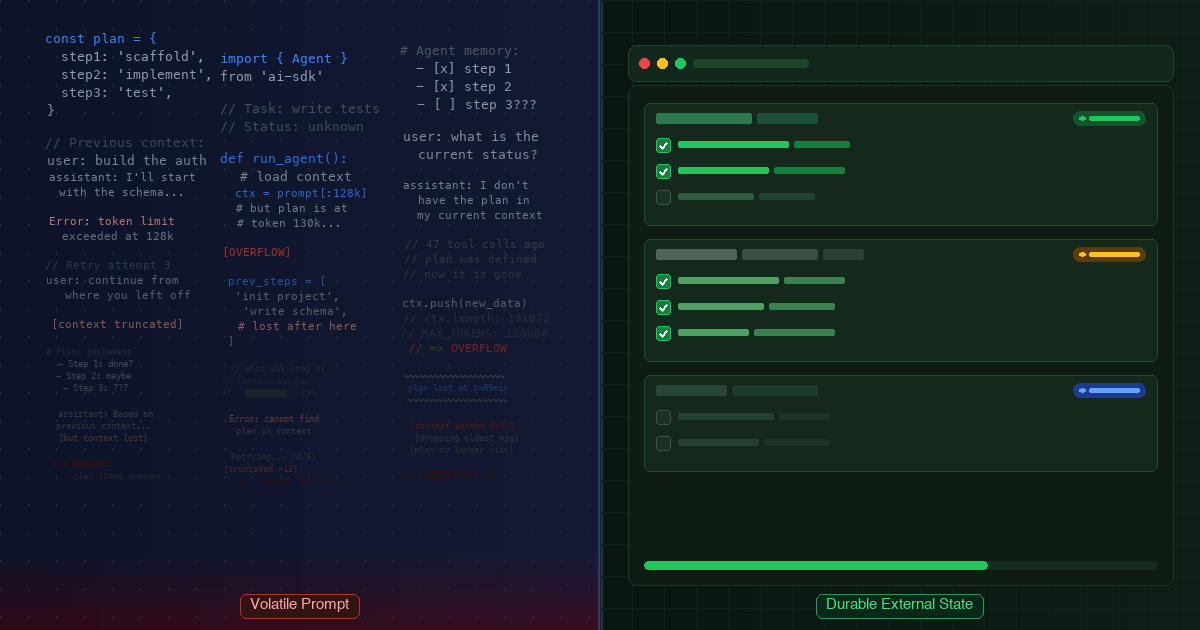
The failure usually shows up the same way. AI coding agents — Claude Code, Cursor, Codex — start clean. The first tasks are sharp. Then the prompt gets longer, the session gets older, and the agent starts to miss constraints it already saw, rework something that was done, or claim "done" against criteria that are no longer visible.
That is not a mystery bug. It is the predictable behaviour of long-context models under pressure: relevant information becomes harder to recover as the context fills, especially when the important detail sits in the middle of a long prompt [1] [2].
Context rot is the predictable drop in a model's ability to retrieve and use relevant information as input grows. It is not a sign that the model suddenly got dumber. It is a memory problem: the prompt becomes volatile working memory, and the contract of the work gets harder to preserve as the window fills [1] [2] [3].
The practical fix is not "just use a smarter model" or "paste the plan again." The fix is to move the contract of the work out of the prompt and into durable shared state: explicit acceptance criteria, task status, and testable task records the agent can re-read on demand [3] [7] [8].
This post explains why that works, why prose plans fail first, and what the externalized version looks like in practice. If you already know the multi-agent handoff problem, you can treat this as the single-session sibling of Multi-Agent Orchestration with Claude and Codex. If you want the feature-level board pattern that sits one layer up, see Coordinating Multi-Task AI Workflows with Work Units.
The Hour-Two Drift: When AI Coding Agents Lose the Plan
The audience for this piece is small on purpose: engineers running long-session AI coding agents.
They know the pattern already. The agent is fine at first. Then the session crosses a threshold - not a formal token limit, just a practical one - and the work starts to drift. The model misses a rule, rewrites an already-correct file, or reports a task complete before the actual checks are satisfied.
That failure mode is not anecdotal. The original "Lost in the Middle" paper found that model performance drops when relevant information must be recovered from the middle of long contexts, and Chroma's 2025 "Context Rot" work showed that performance varies significantly as input length changes, even on simple tasks [1] [2].
The shape of the failure matters. Most teams diagnose it as "the agent forgot the plan," then respond by pasting the same plan back into a bigger prompt. That feels logical. It is also the wrong lever.
The more useful diagnosis is this: the prompt was being used as both working memory and system of record. Once the session gets crowded, those two jobs collide.
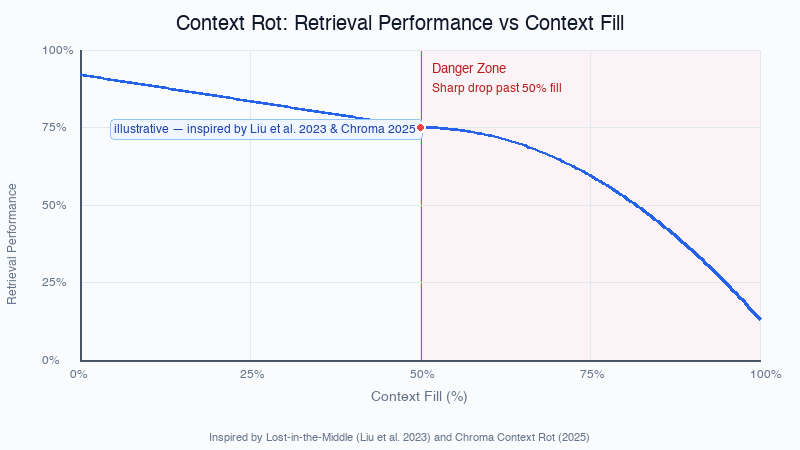 _Model retrieval performance drops predictably as the context fills — the prompt is volatile working memory, not a vault. (Illustrative — inspired by Liu et al. 2023 & Chroma 2025)_
_Model retrieval performance drops predictably as the context fills — the prompt is volatile working memory, not a vault. (Illustrative — inspired by Liu et al. 2023 & Chroma 2025)_
You can see the difference in how people talk about the session after it goes bad:
- "It re-implemented the helper I already wrote."
- "It ignored the constraint I put at the top."
- "It said done, but the acceptance criteria were not actually met."
Those are not three separate bugs. They are three symptoms of one problem: the work contract was trapped inside a volatile prompt.
The wrong diagnosis: more context is not more memory
Bigger context windows help. That part is true. But the evidence does not support the idea that a larger window solves the underlying memory problem.
Anthropic's guidance on context engineering treats context as a finite resource with diminishing returns, and says that as token counts rise, recall gets less reliable. In other words, the window is not a vault. It is an attention budget [3].
Chroma's July 2025 study of 18 models makes the same point from another angle: performance does not degrade only when the prompt is absurdly large. It degrades as input grows, and a single distractor can hurt performance relative to a focused prompt [2].
That is why "just make the prompt longer" is a trap. A longer prompt can improve recall of a few important details, but it also increases the amount of noise the model must sift through. Once the session is crowded enough, the agent must decide what matters most. That decision is exactly where drift starts.
The useful mental model is not "more tokens = more memory." It is "more tokens = more things competing for attention."
| What you are trying to do | What actually happens |
|---|---|
| Keep the plan alive inside the prompt | The prompt gets denser, and the contract becomes harder to retrieve |
| Add more prose for safety | The model has to re-rank more text on each pass |
| Rely on recall alone | The agent reconstructs the work from partial memory |
The next question is not "how do we add more memory?" It is "what format survives context pressure?"
Why prose plans break first
Prose is a terrible system of record for agentic work.
It is too long to scan reliably, too ambiguous to verify quickly, and too easy to drift from after a few turns. A plan written as a paragraph feels durable because it is human-readable. In practice, it is fragile because the agent has to reconstruct the contract every time it revisits it.
MAST's failure taxonomy helps explain why. Across more than 1,600 annotated traces, the researchers found 14 failure modes across three broad categories: system/specification design, inter-agent misalignment, and task verification [4]. Even though that paper studies multi-agent systems, the lesson carries over cleanly: failures cluster when the contract is weak, ambiguous, or hard to verify.
In a single long session, prose plans fail for the same reason. They blur three different things:
- What the work is trying to achieve.
- What counts as complete.
- What has already been done.
Once those are blended together, the agent starts to infer the missing parts. Inference is useful for creativity. It is dangerous for completion criteria.
This is where people often reach for "notes" or "summaries." Those can help, but only if they are structured enough to be re-read as state rather than as memory prose. A plain paragraph summary still asks the model to interpret the contract. A checkable criterion does not.
What survives pressure is not a richer narrative. It is a smaller, more testable unit.
The most compression-resistant unit of memory in this workflow is an acceptance criterion: a short, explicit statement that can be checked again later without re-reading the whole prompt.
What survives context pressure: acceptance-criteria-as-state
An acceptance criterion is not just a quality checkbox. In an agent workflow, it is a state object.
It tells the agent what must be true, not just what should be remembered. That is why it survives context pressure better than prose: it is short, structured, and re-readable.
This is the shape that matters:
{
"title": "Write the draft",
"status": "active",
"acceptanceCriteria": [
{ "text": "Every factual claim maps to a source in RESEARCH.md", "checked": false },
{ "text": "The draft includes the required internal links", "checked": false },
{ "text": "Every declared asset slot appears in the draft", "checked": false }
],
"testCases": [
{
"text": "Re-open the task after a fresh session and continue without re-pasting the whole plan",
"testType": "integration",
"checked": false
},
{ "text": "Verify the criteria still read cleanly after the prompt has grown", "testType": "e2e", "checked": false }
]
}That structure matches the live Agiflow task schema: tasks support explicit acceptanceCriteria items, testCases, status, priority, tags, description, and assignment fields [7]. The project-management domain also treats status as semantic state - backlog, active, review, done, blocked, cancelled - which is exactly the kind of durable state you want an agent to re-read instead of reconstructing [8].
This is the architectural shift:
- Prose plan: "Here is what I think the work is."
- Acceptance criteria: "Here is what must be true for the work to count."
The second version is smaller, easier to verify, and harder to misremember. It is not perfect. But it is much closer to a stable contract.
What to externalize, exactly
The point is not to turn the board into a transcript. The point is to keep only the durable parts of the work outside the prompt.
For a long coding session, the useful external state is usually just five things:
| State item | Why it belongs outside the prompt |
|---|---|
| Objective | It tells the agent what the work is for, even after a session reset |
| Scope boundary | It prevents "while I am here" drift into adjacent work |
| Acceptance criteria | It defines completion in checkable terms |
| Test cases | It turns completion into something that can be verified again |
| Status | It tells the agent what has already been finished and what remains |
That distinction matters because the prompt is a terrible place to store the answer to "what comes next?" A long prompt keeps too many candidates alive at once. A task record with a short objective and explicit criteria makes the next move obvious.
The cleanest version of the board therefore behaves like a memory filter: keep the contract, keep the checks, keep the status, and let the rest evaporate when the session ends.
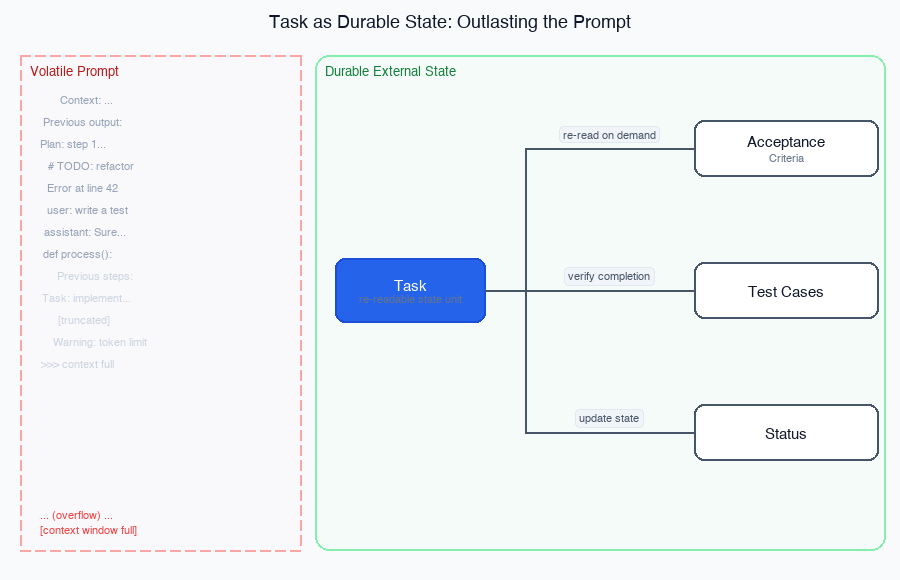 _A task record is not a note — it is a checkable state surface: objective, criteria, tests, status._
_A task record is not a note — it is a checkable state surface: objective, criteria, tests, status._
The reason that matters is simple: the agent does not need perfect recollection of the whole conversation. It needs a compact, checkable state surface that tells it what to do next and how to know when it is finished.
That is the thing prose plans are trying, and failing, to be.
What that looks like in Agiflow
Agiflow is the honest example here, not the hero of the story.
It does not run or host the agent. The agent stays the agent. Agiflow supplies the board: a place to store tasks, explicit acceptance criteria, status, and related test cases so the assistant can re-read the contract over MCP instead of trying to hold the whole thing in prompt memory [8].
That boundary matters. If the assistant loses track of the plan, the fix is not to ask the board to think harder. The fix is to make the work legible as state.
Source-attributed reporting on MCP adoption suggests that this is not a niche transport choice anymore: the ecosystem has crossed 97M+ monthly SDK downloads and more than 10,000 active public servers, according to reporting compiled from Anthropic's December 2025 update and registry snapshots [5]. In other words, "the agent can read and update a shared board over MCP" is now normal plumbing, not a moonshot.
Here is what that durable state looks like in practice:
{
"title": "Draft the blog post",
"status": "active",
"acceptanceCriteria": [
{ "text": "Every claim is cited from RESEARCH.md", "checked": false },
{ "text": "The draft includes the three required internal links", "checked": false },
{ "text": "Hero, OG, proof, and diagram slots are all present in the draft", "checked": false }
],
"testCases": [
{
"text": "A fresh session can re-open the task and continue without re-pasting the full plan",
"testType": "e2e",
"checked": false
},
{
"text": "The agent can update checklist items after each section without losing the original scope",
"testType": "integration",
"checked": false
}
]
}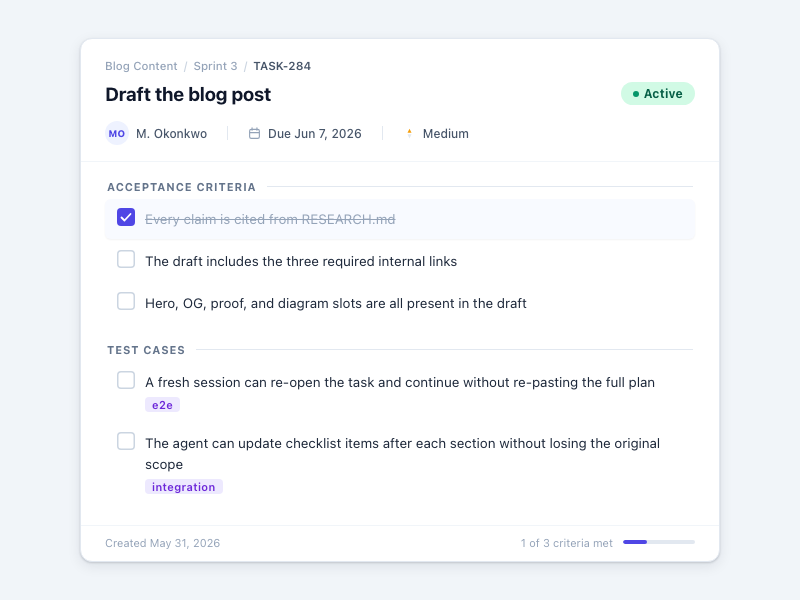 _A task record in a shared board: the assistant reads the contract, checks off criteria, and updates status — without re-pasting the plan._
_A task record in a shared board: the assistant reads the contract, checks off criteria, and updates status — without re-pasting the plan._
The important thing is not the exact UI. It is the shape of the record.
If the session is fresh, the agent can still answer three questions by reading the task:
- What are we doing?
- What counts as done?
- What is still missing?
That is enough to keep the work moving after the context has started to fray. It also makes review easier, because the same state that guides the agent can be checked by a human.
The counterargument: won't bigger windows or smarter memory features solve this?
They will help, but they will not remove the need for external state.
If you have ever worked in a long session with a larger model, you already know the trade-off: the window lasts longer, but the task still needs to be re-established once the work gets dense enough. Chroma's findings make this explicit - degradation shows up as context grows, not only at some mythical maximum token count [2]. Anthropic's guidance says the same thing in plainer language: context is finite, and recall gets less reliable as the budget fills [3].
So yes, better models and better memory features improve the margin. But they do not change the underlying architecture problem. A long prompt is still a volatile place to keep the contract of work.
The stronger pattern is to split the jobs:
- The prompt handles the current turn.
- The board handles the durable contract.
- Acceptance criteria tell the agent whether the work is actually done.
That split is why this is a memory problem instead of an intelligence problem. The model can be competent and still drift if the contract lives in the wrong place.
If you want the boundary one layer up, the handoff problem is covered in Multi-Agent Orchestration with Claude and Codex. If you want the broader board mechanics, see Coordinating Multi-Task AI Workflows with Work Units. If you want the token-budget version of the same argument, read Token Efficiency in AI-Assisted Development.
The practical takeaway
Do not ask a long prompt to be a database.
Keep the plan short in the prompt, move the contract into durable shared state, and make the completion criteria explicit enough that AI coding agents can re-read them after the session has aged. That is the difference between "the model forgot" and "the system was designed to preserve what mattered."
If you want the board version of that pattern, the work-units example is the next read. If you want the single-session version of the same idea, keep this rule in mind: prose explains the work, but acceptance criteria survive the work.
References
[1] Lost in the Middle: How Language Models Use Long Contexts - https://arxiv.org/abs/2307.03172 - Relevant because it shows performance drops when models must recover information from the middle of long contexts.
[2] Context Rot: How Increasing Input Tokens Impacts LLM Performance - https://www.trychroma.com/research/context-rot - Relevant because it shows performance varies as input length changes and does not degrade only at the extreme end.
[3] Effective Context Engineering for AI Agents - https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents - Relevant because it frames context as finite and recommends structured notes or memory outside the context window.
[4] Why Do Multi-Agent LLM Systems Fail? (MAST) - https://arxiv.org/abs/2503.13657 - Relevant because it identifies specification, misalignment, and verification failures that map cleanly onto weak work contracts.
[5] MCP Adoption Statistics 2026 - https://www.digitalapplied.com/blog/mcp-adoption-statistics-2026-model-context-protocol - Relevant because it supports the claim that MCP is now normal infrastructure for assistants reading and updating external tools.
[7] Agiflow create_task MCP tool schema - internal product-knowledge MCP - Relevant because it verifies first-class acceptanceCriteria, testCases, and status fields on tasks.
[8] Agiflow project-management domain - internal product-knowledge MCP - Relevant because it verifies task status categories, work-unit grouping, artifacts, workflow locks, and the boundary that Agiflow does not run the agent.
More to read
Multi-Agent Orchestration with Claude and Codex: Role Separation, Handoff Contracts, and Verification Gates
Architect multi-agent code systems that stay coherent. Learn role separation patterns, handoff contracts, and verification gates to prevent coordination failures.
18 min readIntroducing the Agiflow CLI: Scaling AI Agents Across Machines
GitHub Actions was never built for the fast closed loop an agent needs — going back, redoing a step, fixing its own work. Local agent fan-out solved the loop on one laptop and broke on two. The Agiflow CLI is the convenience wrapper we use internally to drive workflow locks, work units, and artifacts through the Agiflow API — so agents on different machines can pull the same backlog without stepping on each other.
8 min readRoadmap to Build Scalable Frontend Applications with AI: Atomic Design System, Token Efficiency, and Design Systems
Learn how to architect frontend applications that scale with AI assistance. Discover how atomic design methodology, component libraries, and design systems dramatically reduce token consumption while ensuring consistent, maintainable codebases.
18 min readPut this project board inside ChatGPT
Open Agiflow in ChatGPT to plan campaigns, create tasks, and check what needs attention. Create a free Agiflow account when you are ready to keep the board for your team.